5.1 개요
선형분류 모델은 몇가지 문제가 있습니다. 선형분류로 분류되지 않는 문제와 템플릿 score 계산 방식으로 봤을때도, 템플릿의 퀄리티가 좋은 성능을 기대하기 어렵습니다.
그래서 뉴럴 네트워크의 핵심은 이런 선형구조에+ 비선형 구조를 더해두는 방식입니다.
1강의 생체인식 방식에서 영감을 얻었다는 것을 생각할 때, 단일 구조-> 복합구조로 구성되는 것과 같은 느낌입니다.

단순히 feature변환을 해서 이러한 데이터도 선형분류를 할 수 있지만, 전제조건이 있습니다. 데이터의 형태를 파악하고 있고, 이 데이터에 맞는 feature변환을 알고 있다고 할 때, 가능합니다. 현실은 고차원상의 기하학적으로 분포되어있는 데이터의 형태를 알 수없습니다. 강의에서는 몇 가지 컴퓨터 비전분야에서 이러한 Feature Transforms을 어떻게 하고 있는지 이야기 합니다.
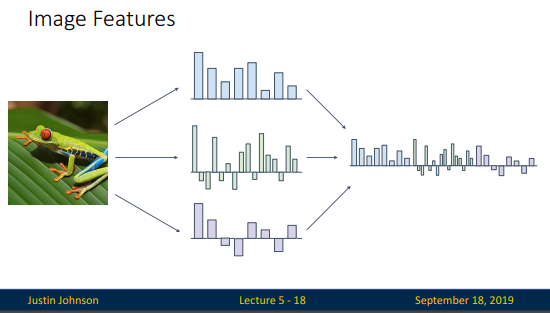
Color Histogram방식과 Histogram of Oriented Gradients(HoG)방식, Data-driven방식입니다. 그리고 이세가지 방식을 서로 연결시켜서 위의 슬라이드 처럼 하나의 high dimensional feature vector로 사용해 왔다고 설명합니다.
이번강의의 학습목표? Everyone should attempt ones own results luotettavia nettikasinoita. 는 linear 모델의성능이나쁜것을 neural networks를사용해서해결할 수 있다는 것을 이해해보려고 합니다.
5.2 Fully-connected neural network
컴퓨터 비젼 분야에서 2011년까지 이러한 방식으로 잘 사용해 왔지만, 2012년 딥러닝이 나오면서 혁신적인 기술 발전이 이루어집니다. 딥뉴럴 네트워크는 피쳐추출과 피쳐분류을 연결한 것이며, 피쳐추출 방식도 학습을 통해서 스스로 하도록 만드는 것입니다. 스스로 한다는것은 이 피쳐추출 부분에서도 전체 Loss를 최소화 하는 방식으로 반복학습을 통해서 가능하도록 하는 것입니다.

뉴럴네트워크는 선형과 비선형을 복합구성한 방식입니다. 위 슬라이드는 2-layer Neural Network의 일반적인 형태를 나타내며 아래와 같은 형태로 neural network layer를 쌓아갈 수 있습니다.

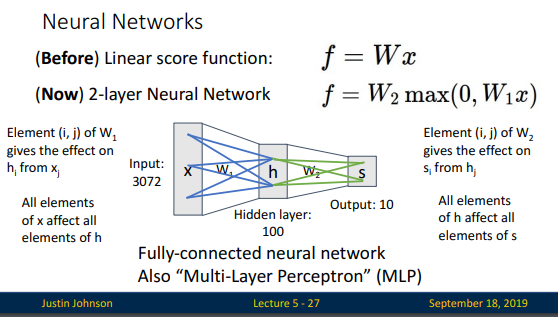
Fully-connected 는 다음의 블로그에서 한 방에 이해하고 오겠습니다.
- 완전연결계층[Fully connected Layer] _데이터 사이언스 사용 설명서 blog
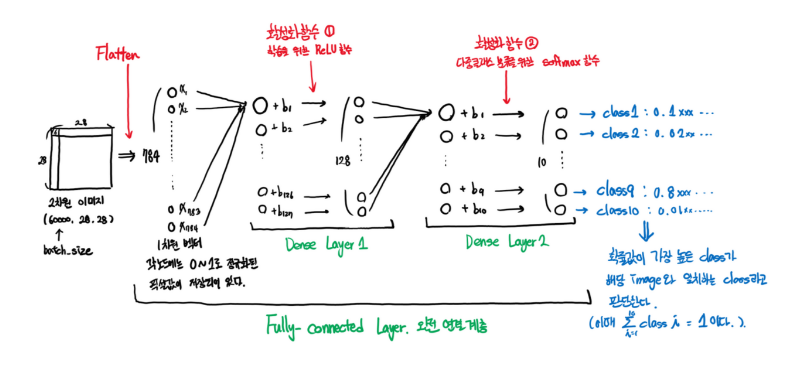
활성화 함수까지 모두 이해하고 오셨나요?
강의 슬라이드 37page까지 설명은 넘어가도록 하겠습니다. 숙명여대 강의가 있으니, 확실히 이해가 빠릅니다. 숙명여대 강의가 뉴럴네트워크부분에서 두번으로 나누어져 있으니, 이제 다음 강의링크로 넘어가겠습니다.
참고적으로 앞에서 보았던 간단한 neural network system을 pytorch가 아닌 numpy를 사용하여 구현한 형태의 코드를 통해 확인해 보겠습니다.

위의 코드는 다음과 같은 과정을 거쳐 설명된다
- 1. Initialize weights & data
- 2. Compute loss(using sigmid activation & L2 loss)
- 3. Compude gradients
- 4. SGD step
이러한 코드는 매우 간단하게 구현되었지만 위의 코드를 돌려보면 실제로 neural network가 학습하는 것을 볼 수 있습니다.
슬라이드 43~51까지는 패쓰~ 하겠습니다.
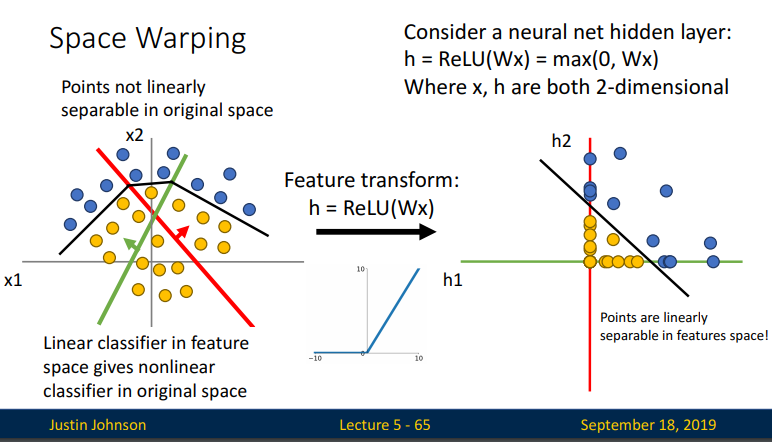
5.3 Space Warping
이제 부터는 비선형적인 활성함 함수 Relu를 geometric 관점에서 확인해 보겠습니다.
간단한 2D 선형함수를 생각해보면, input data들이 Relu함수에 의해 어떻게 Feature Transform이 되는지를 보여주는 것입니다. 아래 슬라이드처럼 linear transform(linearly warps the space)시켜보면 두개의 categorical data point들이 새로운 representation으로 나타나지만 여전히 선형적으로 분리가 가능하지 않아보입니다.
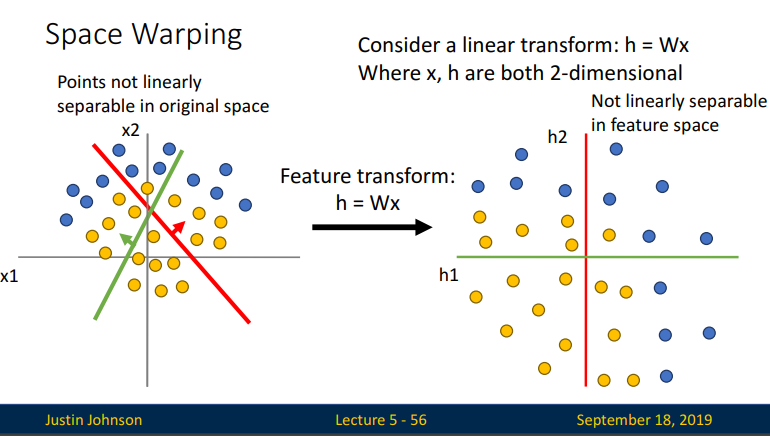
이제 ReLU function을 통해 space warping 시켜보면 region of space가 다음과 같이 나타나게 될 것입니다. 아래 슬라이드와
같이 original scape에서는 point들이 선형적으로 분리가되지 않았지만 ReLU transform을 통해 point들이 선형적으로 분리가 될 수 있다는 것을 볼 수 있습니다. 달리 표현하면 decision boundary가 ReLU transform을 거쳐 linear 하게 바뀌었다는 것입니다.
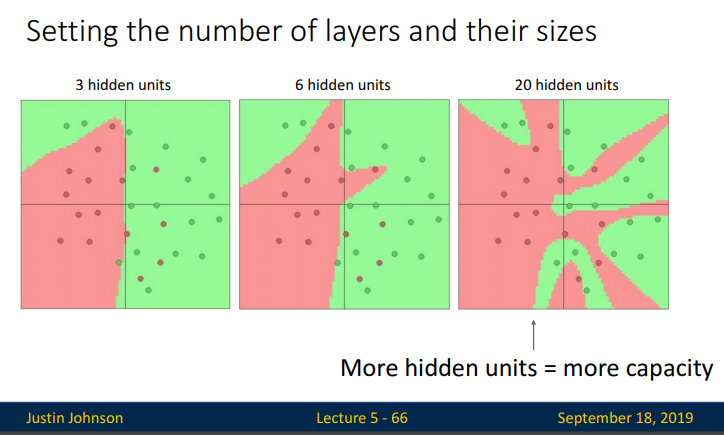
만약 hidden layer를 더 증시켰을때는 어떤 현상이 일아날까요? 위의 슬라이드에서는 왼쪽 그림에서 보이는 검은 선의 꺽인 부분이 레이어에 해당됩니다. 더 많은 꺽임이 생긴다고 보면됩니다. 아래 슬라이드에서 확인하면, hidden layer가 늘어날수록 feature space상에서 훨씬 더 복잡한 representation을 통해 linear하게 분리 가능해질 것이며, 이것은 input space에서 훨씬 더 복잡한 non-linear decision boundary로서 표현되는 것으로 보입니다.
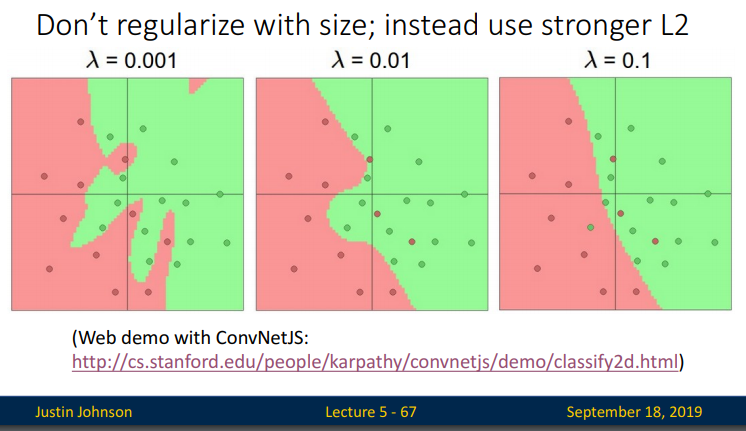
마지막 히든레이어 20개의 사진은 과적합된 모습처럼 보이기도 합니다. 이럴때는 3강에서 람다 정규화를 추가하여 overfitting을 줄일 수 있습니다.
강의가 뒤로 갈수록 앞에서 배운 내용이 나오는게 반갑기까지 하네요. 이제 이번강의의 마지막 챕터인 Universal Approximation에 대해 알아보도록 하겠습니다.
5.4 Universal Approximation
이제부터 배워볼 부분은 NN(Neural Network)의 이론적 증명에 대해서 살펴 보도록 하겠습니다. 증명은 가설이 필요하니, 우리가 예측하고 싶은 f(x)가 있다고 가정하고, 하나의 히든레이어(비선형)를 가진 NN이
이 부분은 수학적 이해가 필요하므로 자세한 내용은 숙명여대 강의를 통해서 확인 할 수 있습니다. (강의 44분 구간[링크])
이해한 대로만 설명을 추가해 보자면, Relu 히든레이어로 구성된 NN에서 출력값을 계산하여 어떤 함수의 근사치를 계산함으로써 증명하는 과정입니다.

죄측하단은 히든레이어 Relu함수의 공식이고, 이를 통해 나온 출력값y가 선형식(형태)으로 표현될 수 있다는 것을 보여줍니다.
이것은 비선형성을 가진 데이터를 분류하기위해서 선형분류기의 한계를 relu와 같은 비선형을 가진 함수를 추가해 줌으로써 결국에는 선형성을 가진 출력값으로 표현되는 과정을 보여주는 것입니다.
우측의 그래프는 ReLU activation을이용하면, 계단식함수를만들수있다는것을 보여줍니다. 이러한 함수를 “bump function”이라고 합니다. 그러면 아래 슬라이드는 히든레이어 하나당 이런 계단식 그래프를 구할 수 있고, 연결하면 이런식의 그래프가 나온다는것을 설명합니다.
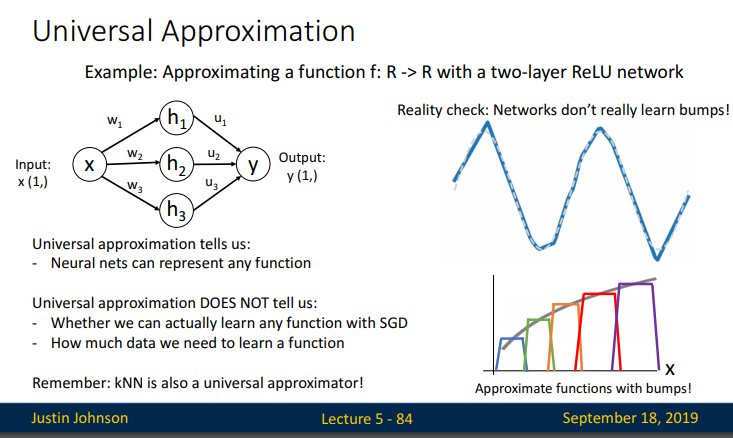
이 bump function은 4개의 hidden layer로 이루어졌지만 위의 그림처럼 우리는 8, 12, 16…개의 hidden unit을 가진 neural network를 4-hidden unit bump function을 기준으로 K배 해준 모든 bumps 들을 더해주어 최종 함수를 build할 수 있게 됩니다. 이 이론적 증명은 NN이 상업적으로 발전하기전인 1980년대? 부터 나와있었지만, 컴퓨팅 계산으로 실제로 최적의 w를 어떻게 찾을 것인가에 대해서는 오랫동안 풀지못한 과제였다고 합니다.
그리고 실제로 neural network가 이러한 bump function을 학습하지는 않으며, 이것은 neural network의 원리를 설명하고자 할 때 수학적인 구조로써 사용되는 이론이라고 합니다. 또한 이것은 optimization이 어떻게 동작하는지 설명하지 못한다는 점이 있기에 optimization을 설명 할 수 있는 또 다른 방법으로 강의를 마무합니다.
5.5 Convex Functions
convex의 정의: 함수 f(x)가 있을 때, 특정 두 지점을 찍었을 때, x축을 기준으로 t라는 비율로 된 곳의 값을 함수 f에 넣은 것은 각각의 함수 값 f(x)와 f(y)에 대해서 같은 비율을 적용한 것 보다 적은 값을 가지는 것이 Convex다.
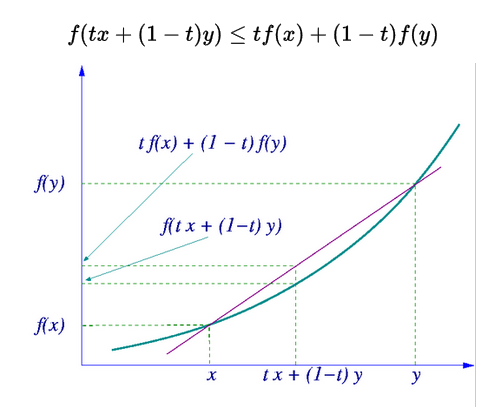
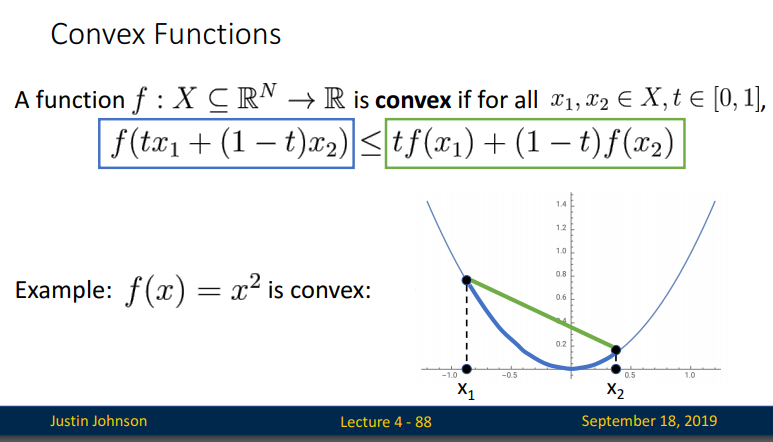
강의에서는 위와 같이 설명하고 있네요. 정의느.. 명쾌해서 좋습니다. 개운해요.
왜 convex함수의 정의가 필요할까요? 이제부터는 loss function을 W의함수로서살펴보려고 합니다. xi, yi 데이터가모두들어왔을때, Neural Network로만든s= f(xi;W)를이용해서손실함수(loss function, W의함수)를만들면, nonconvex성질이나타나게된다고 합니다. loss function을 W의함수로봤을때, neural network기반함수가 convex하지않음을 살펴보려고 convex의 정의가 필요했네요. 정의의 조건을 만족시키지 못하는것으로 증명이 될테니까요.
그렇다면, convex하지않다는것은무엇일까요?
적어도하나의 (x1, x2)에대해, 두점을연결하는선분이 주어진곡선보다위에있다면, 해당함수는 nonvex 함수다.
아래 cos(x) 함수와 같이 말입니다.
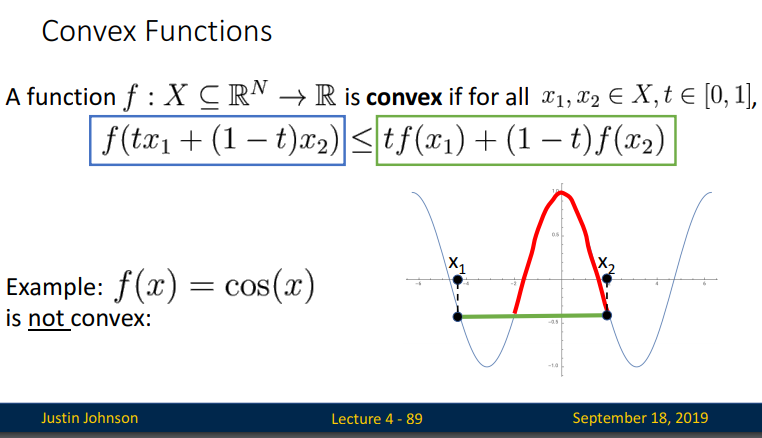
위 그림에서 보듯이 cos(x)는 convex function이 아닙니다. 이러한 convexity를 좀더 일반적인 다차원 함수(high-dimensional function)으로 나타내면 다음과같은 bowl 모양의 함수로 나타난다.

convex함수는 최솟값이단 1개이므로. (gradient = 0인점이 1개뿐이므로, 언젠가는그최솟값으로반드시도달하게된다.)loss function들이 optimization을 위해 미분을 하면 convex function이 되어 global minimum에 도달하기 위한 theoretical guarantees를 제공하기 때문에 중요합니다.
하지만 대부분의 NN은 이러한 guarantees가 존재하지 않습니다. 다시말해, 대부분의 neural network system 은 non-convex optimization이 필요하다는 것입니다. 대부분의 neural network based loss function은 W에대한 convex 함수가아닐확률이크기 때문입니다.

앞에서 배웠던 SDG변형들이 global minima를 찾아준다는 가설을 가지고 사용을 하고 있을 뿐이라는 것입니다.
그러면서 자연스러운듯 부자연스럽게 다음 강의에 대한 안내를 끝으로 마무리가 되네요.

출처 : https://sunnyyanolza.tistory.com/24