3.1 선형 분류(Linear Classification)
앞서 2강에서 추천한 홍콩과기대 김성훈 교수님의 머신러닝 2강을 들었다면, 선형에 대한 이해는 되었으리라 생각됩니다. For additional information and facts, refer to your parhaat online-casinot.
우리의 생활에서 얻어지는 대부분의 데이터는 선형(linear)적인 모형으로 설명할 수 있는 경우가 많습니다. 데이터를 통해서 선형적인 가설(hypothsis)을 세운다는 것은 선형모델의 분류와 회귀문제에 있어서 시작점이 되는 과정이 될 것입니다.
신경망 모델을 공부할 때에도 이 기본적인 선형모델을 아는 것이 매우 중요합니다. 복잡한 신경망을 만드는 기본 구조는 선형분류기 이기 때문입니다. 앞서 2강에서 KNN 알고리즘의 장단점을 살펴보았습니다. N개의 데이터를 하나하나 계산하는 KNN방식은 이미지분류에 적합하지 않은 알고리즘 이었습니다. 그렇다면 정반대로 전체적인 패턴을 학습하여 분류하는 방법을 생각해 봅시다.
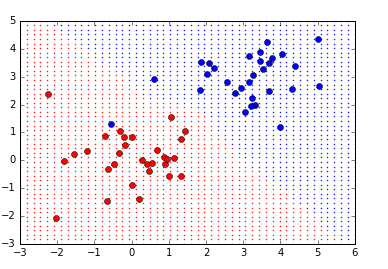

위의 k=5인 최근접 이웃의 그림을 보면 빨간색과 파란색 사이를 가로지르는 하나의 경계선을 볼 수 있습니다. 만약 각각의 사례 대신에 이 경계선 하나를 학습할 수 있다면 최근접 이웃의 여러 단점들을 극복할 수 있습니다.
먼저 가장 단순하게 이 경계선이 직선의 형태라고 한다면, 이를 선형 분류(linear classification)이라고 합니다. 선형 분류는 단순하기 때문에 학습도 쉽지만 과적합에도 강합니다.
위의 예에서 가로축을 x1이라 하고 세로축을 x2라고 하자. 다음 같은 선형 모형을 만듭니다.
위의 식을 자세히 보면 선형 회귀와 식 자체는 동일하다는 것을 알 수 있습니다. 한 가지 다른 점은 가 데이터에서 나오는 값이 아니라는 것입니다. 다시 이제 강의로 돌아가서,

y 대신 F(x,w)가 쓰인 유사한 식을 확인할 수 있습니다. 선형분류기(Linear classifier)를만든다는의미는, f(x,W)라는함수를하나만드는것입니다. 위의 슬라이드는 CIFAR-10에서 X입력값을 3072 사이즈의 flattend된 벡터 입력값, W는 [10 x 3072], b는 [10 x 1]의 크기를 가지므로, 3072개의 숫자들(raw 픽셀값)이 함수로 들어오고 10개의 숫자들(class scores)이 함수에서 나옵니다. w는 파라미터이며, 가중치(weights)라고도 불리고, b는 편향 벡터(bias vector)라고 불립니다.
*이 강의 전반적으로 b는 있고, 없고 동일하게 취급합니다. 꼭 설명하지 않아도 항상 존재하거나 없어도 설명에 큰 영향을 주지않는 값입니다. 그러니 이후로 슬라이드에 b 가 안보여도 크게 의미를 두지 않겠습니다.
다시 말해서 X라는 input에 대해서 f(x,w)라는 output 이 score를 갖는 10개의 클래스 로 나온다는 것을 의미합니다.
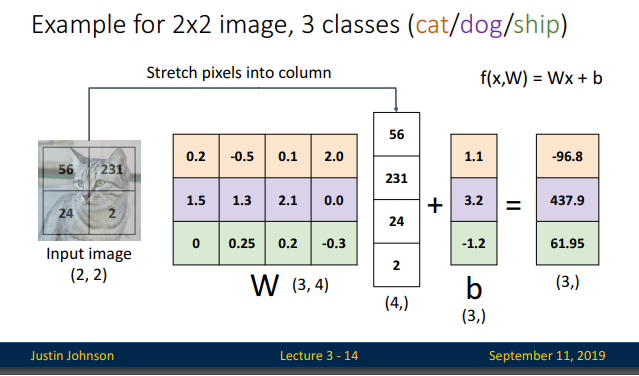
슬라이드 3-14에서 마지막에 출력된 스코어 값이 예를들어 -96.8은 개에 대한 입력이미지의 score , 437.9는 고양이에 대한 score, 61.95가 자동차에 대한 이미지의 score라고 한다면, 이 입력된 이미지는 가장 높은 score 를 받은 고양이로 분류됩니다.
3.2 선형분류기 세가지 관점
Algebraic / Visual viewpoint /Geometric viewpoint
1. 대수적(Algebraic) 관점에서의 선형분류기는 선형분류기를 matrix와 vector의 multiplication 수학식으로이해하는것입니다. 이부분에서 선형대수와 벡터 , 스칼라와 같은 것들을 읽고 왔는데, 몇 번을 읽어도 수학적 이해는 성취도가 오르질 않네요.
일단은 선형대수의 느낌만 이해해보자. 선형대수란 어떤 함수가 선형(linear) 함수일 때 그 함수의 성질을 배우는 것으로, 벡터와 행렬을 주로 다루는 수학이다. 복잡한 비선형 문제를 간단한 선형 방정식으로 변환하여 문제를 해결할 수 있어, 컴퓨터 그래픽 등의 다양한 분야에서 활용된다. 머신러닝에서는 PCA 등을 이용하여 차원(dimension)을 줄이거나, 학습(training)할 때 계산 과정을 줄이는 데 활용된다. 선형대수는 링크를 통해서 학습하고 오겠습니다. 문과생을 위한 딥러닝_블로그 [링크]
W의 row를하나씩떼어서이미지와같은 2 x 2 픽셀구성으로만든다. 즉, x와 W를내적(elementwise multiplication)하는것은W라는필터를거치는행위이다. 행렬곱 연산을 통해서 나오 결과값 즉, 각 class에대한필터를거쳐서나온결과는각 class에대한 score이므로, 이것을 linear classifier로이해할수있다. 는 관점이다. 이미지 라는 고차원의 데이터를 2차원이라는 저차원 공간 벡터로 나누어 생각해도, 아래서 보듯이 의 모든 행은 한 클래스의 classifier라고 보는 것입니다.
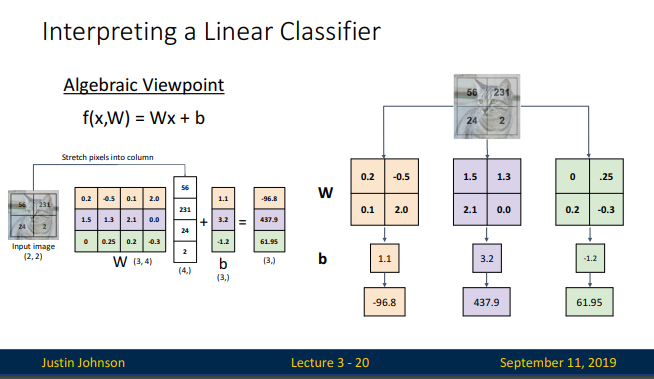
선형대수를 이해하고 머신러닝을 공부한다면, 더없이 좋겠지만, 일단은 선형대수에 대한 느낌만 가지고도 이미 이러한 계산을 해주는 함수들이 정착되었기 때문에 머신러닝을 구현하는데는 어려움이 없을것으로 생각하고 넘어가겠습니다.
2. Visual viewpoint
weight W에 대한 또 다른 해석은 W의 각 행이 클래스 중 하나에 대한 template(또는 prototype)이라는 것입니다.
이미지의각클래스 스코어는각템플릿들을 이미지와 내적을통해 하나 하나 비교함으로써 계산되며, 이 스코어를 기준으로 가장잘매칭되는것이 무엇인지정한다는 것입니다.
즉, 선형분류기가 결국템플릿 매칭을 하고 있고, 각템플릿이 학습을통해 배워집니다.
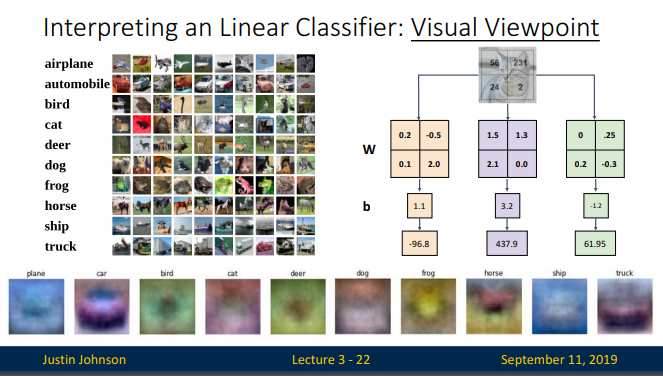
템플릿의 결과물이 눈으로 봐도 좋지 않습니다. 단일 linear classifier는 정확한 분류를 해주기에 적합하지 않습니다. 이 후에 배울 신경망이 이 작업을 수행할 수 있게 해줄 것입니다. 신경망은 hidden layer에 중간 뉴런(intermediate neurons)을 두어 특정 차종(가령, 왼쪽을 향한 녹색 자동차, 앞쪽을 향한 파란색 자동차 등)을 감지할 수 있게 하며, 그 다음 층의 뉴런은 개별 자동차 검출기(detector)에 대한 weighted sum을 통해 보다 정교한 탬플릿(자동차 score)을 얻을 수 있을 것입니다.
3. Geometric viewpoint
기하학적관점으로이해하는것입니다. 이미지들을고차원의벡터로펼쳐냈으므로, 각벡터들은고차원공간상의하나의점에해당됩니다. f(x, W)함수는공간상의선형함수가되고, 공간상에서점을분류하는 classifier의역할을하게 된다는 것입니다.
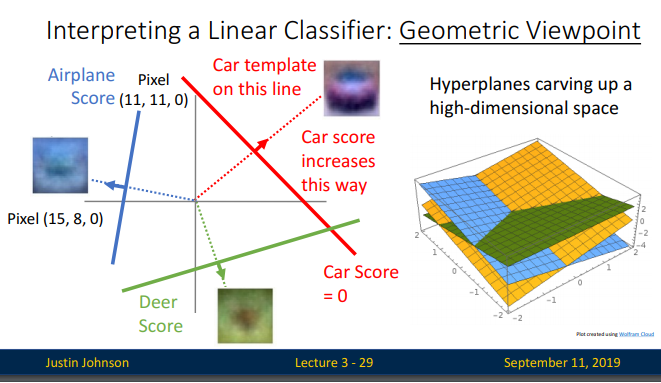
여기까지 정리하고 나니, 선형분류기의 세가지 관점을 왜 이렇게까지 정리했나 싶은 생각 듭니다. 중요한 것은 이러한 선형분류가 XOR를 해결할 수 없다는 것입니다. 위의 세가지 선형분류기의 특징을 살펴봄으로써, 아래의 문제점을 드러내기 위함이었죠.

W의각 row를필터로이해하는 algebraic viewpoint, 템플릿으로이해하는 visual viewpoint, 그리고고차원공간상에서초평면으로공간을나누어이미지벡터를분류하는 geometric viewpoint가있습니다.
Classifier의궁극적인목표는 true class에대한점수를높게설정하는것이다. 슬라이드의예시를보면, 고양이이미지를 dog로, 자동차이미지를 automobile로, 개구리이미지를 truck으로분류하고 있습니다. 3개의예시중 2개가오분류되었으며, 특히개구리샘플에서의성능이매우 덜어집니다.
우리가이미지분류를위해사용한 score function인 f(x, W) = Wx + b의 W가좋지않았기때문입니다.
그렇다면어떻게좋은 W를찾을수있을까요? 여기서 3강의 핵심인 손실함수(Loss function) 의 이야기가 시작됩니다.
- 김성훈 교수님의 ML-lec03 cost fuction [링크]
3.3 손실함수 (Loss Function)
앞서 선형분류에서 각 입력값에 곱해지는 W에 대해서 살펴봤습니다. 최적의 W를 찾아내는 것이 우리의 목적입니다. 그러면 어떻게 W를 찾아낼까요? 우리는 한 번의 학습을 통해서 출력값(score)을 얻어냈습니다.
그러면, 이 출력값이 우리가 기대한 예측값과 정확히 맞는지 확인해 보는 것으로 W를 조정할 수 있습니다.
입력값 Xi는 이미지는, 출력값 yi는 label에 해당합니다.

우리가 예측해야할 예측값과 실제 선형분류기를 통과해서 나온 출력값의 차는 결국 우리가 만든 선형분류기의 성능을 평가하는 지표가 됩니다. 이 차이가 작을 수록 우리는 높은 정확도를 가졌다고 할 수 있습니다.
이 차이값을 LOSS FUNCTION 이라고 합니다. 결론부터 얘기하자면, linear classifier의 Loss는각 sample의 loss들의평균값입니다.
김성훈 교수님의 선형회귀 강의에서는 손실함수를 다음과 같이 정의합니다.
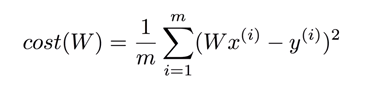
모양은 약간 다르지만, 같은 내용입니다. 이 손실함수가 convex 형태를 가진다는것을 강의를 통해 확인할 수 있습니다.
CS231n강의에서는 이러한 손실함수의 2가지 종류를 소개합니다.
3.3-1 Multiclass SVM loss(Support Vector Machine)
이 손실함수는 Hinge Loss라고도 불립니다. 위에서 살펴본 손실함수와 비슥하지만, 조건이 생겼습니다.

sj는 ‘정답이 아닌’ 클래스의 스코어, syi는 ‘정답’ 클래스의 스코어 입니다.
즉 1에서 정답 스코를 뺀값을 정답이 아닌 스코어와 빼줄경우 즉, 오답인 스코어값이 클경우 그 값을 Loss로 취하고, 정답이 높아서 오답에서 정답을 뺀 값이 클경우 음의 값이 나와서 loss함수는 ‘0’의 값을 취하게 됩니다.
sj +(1-syj) > 0 (즉 정답이 1보다 크고, 정답이 아닌 클래스보다 크면 음의 값이 나오느로, 이것은 정답 스코어가 높다는 뜻이므로 당연히 로스가 ‘0’을 취한다.)
그렇지 않은 경우라면, 정답이 아닌 클래스 스코어(sj) – 정답 클래스 스코어(syi) + safety margin(여기서는 1) 값을 loss로 한다.
syi가 sj보다 충분히 커야 잘 분류했다고 할 수 있다.
이 모양이 경첩처럼 생겼다고 해서 hinge loss라고 이름이 붙여졌다.

최종적으로 loss를 다 더하고 (2.9 + 0 + 12.9) 클래스가 3개니 3으로 나눠서 평균을 구하고, 그렇게 계산된 5.27이 최종 loss가 됩니다. 여기서 질문을 굉장히 많이하네요.
Q1. 자동차 점수가 살짝 바뀌면 loss는 어떻게 될까요?
- loss는 변하지 않을 것입니다. 계속 loss는 0일 것입니다.
Q2. loss의 최소/최대는 무엇일까요?
- 최소=0 / 최대=무한대
Q3. 초기화에서 W가 매우 작고 모든 s는 거의 0에 가까울 때, loss는 무엇일까요?
- loss = (클래스 수)-1 이 경우, loss는 항상 (클래스 수)-1의 결과를 보이므로, 다른 숫자가 나온다면 초기화가 잘못된것으로 생각할 수 있습니다. 따라서, 디버깅을 할 때 유용하게 사용할 수 있는 방법입니다.
Q4. 모든 클래스에 대해 합을 하는 것이라면 어떻게 바뀔까요? (j=y_i도 포함)
- loss는 1 증가할 것입니다.
Q5. 합 대신 평균을 사용한다면 바뀔까요?
- 변하지 않습니다. 그러므로 크게 중요치 않습니다.
Q6. max의 위쪽에 제곱을 사용한다면 바뀔까요?
- 네. 이 경우에는 달라질것입니다.
Q7. L = 0이 되는 W를 찾았다고 합시다. 그 W는 유일할까요?
- 그렇지 않습니다! 2W 또한 L = 0일 것입니다!
3.3-2Regularization
위에서 제시한 loss function에는 버그가 하나 있습니다. 데이터셋과 모든 예제를 정확하게 분류하는 파라미터 W가 있다고 가정합니다(즉, 모든 점수는 모든 margin을 충족하고 모든 i에 대해 \(L_i = 0)입니다). 문제는 이 W가 반드시 고유하지는 않다는 점입니다.
즉, W는 여러개가 될 수도 있다는 점입니다. W가 여러개 있을 수 있는것이 어떻게 문제가 될까요?
Data loss를줄이는 W를찾는과정이트레이닝데이터에서이루어지기 때문에, 가중치 W는 트레이닝셋에 맞춰져 있습니다.
가중치 W가 테스트셋에도 맞춰져 있을까요? 아닙니다.
이러한 현상을 예로 설명하는 경우가 많은데 , 그중에서 가장적합한 예는 학교에서 시험만 보면 1등하는 학생이 있습니다. 이 학생은 평생을 학교에서 시험만 보도록 훈련되었기 때문에 어떤 문제도 100점을 맞습니다. 그런데 학교를 졸업하고 사회에 나와서도 사회에서 만나는 문제들도 학교시험과 같이 모두 100점을 맞을 수 있을까요? 학교에서는 100점짜리 학생이 사회에서는 10점 , 50점 이라면 학습이 잘못된 것 입니다. 머신러닝 알고리즘도 마찬가지로 트레이닝에서 정확도 100%인것보다 새로운 데이터 또는 테스트 데이터에서 정확도가 높은것이 학습이 잘된 것이고, 이것을 일반화 기능이 높다고 말합니다. 그리고 이렇게 트레이닝에 너무 잘 맞춰진 모델을 과적합(ovrfitting)되었다고 하며, 과적합되지 않도록 해주는것이 정규화( ragularization)입니다.
정규화는 제약을 주는것 입니다. regularization penalty 를 loss function에 추가하면 됩니다.

쉽게 말해서 손실함수는 트레이닝 입장에 있고 regularization은 테스트 입장에 있습니다. 만약 트레인셋에만 맞는 가중치 W를 학습하려고 할때 regulaization은 어느정도 패널티를 부여합니다. 여기서 람다는 regularization strength로 하이퍼파라미터입니다다. 람다 값이 작을 수록 약한 정규화가 되었다고 말합니다.
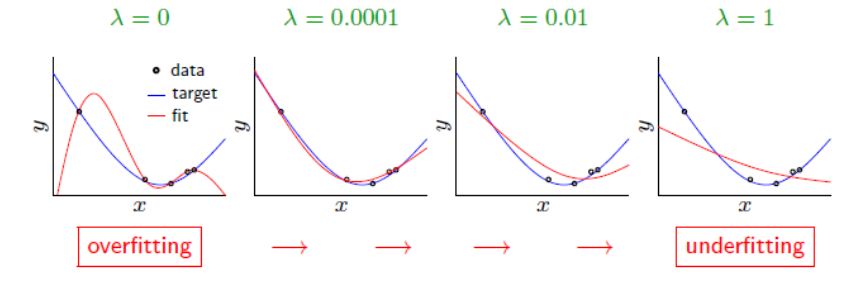
(참고로, L1 regularization을 사용하는 선형 회귀 모델을 Lasso model이라고도 하며, L2 regulaization을 사용하는 선형 회귀 모델을 Ridge model이라고도 한다.)
3.3-3 cross-entropy
multiclass SVM loss 외에도 딥러닝에서 자주 쓰이는 Cross -Entropy 손실함수가 있다.
Cross-entropy loss는분류기가반환한 score function의점수를확률로이해할수있었으면좋겠다는아이디어로시작된다. softmax가 있다.
예를들어, class가 cat / car / frog 세개로분류되며, (xi, yi) 데이터가주어졌다. 따라서 i = 1인경우, 고양이이미지가이미지샘플로주어진다고생각하자. 즉, i = 1일때, yi =1이다.( true class가 1번 cat에 해당)
s1 = 3.2 , s2 = 5.1 , s3 = -1.7

우리에게주어진 s1 = 3.2 , s2 = 5.1 , s3 = -1.7 는 unnormalized log-probabilities / logits 이므로, exp()함수를씌워준다.
(분모) 모든 스코어에 exp를 취하고 그걸 다 더한 다음, (분자) 원하는 클래스의 점수를 exp 취해서 나눈다.
이렇게 되면 ‘확률’ 값이 된다.

그럼 왜 exp와 -log를 붙일까? softmax는 multinomial logistic regression이다.sigmoid function은 위의 그림에서 왼쪽 그래프에 해당된다. 수식을 보면 exp가 취해져있다. 그렇기 때문에 exp를 사용한다.-log를 취하는 이유는 오른쪽 그림과 같다.
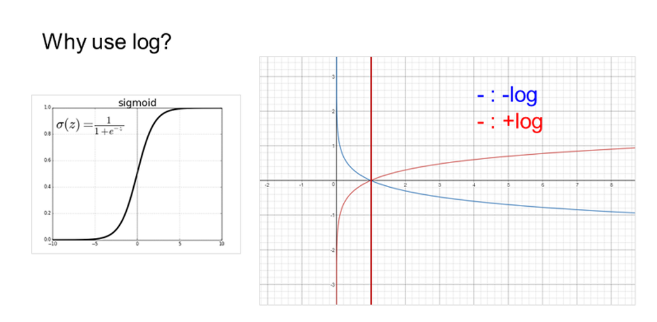
x축이 확률, y축이 loss라고 생각하면, -log가 확률이 1에 가까워질수록 loss가 0에 가까워진다.
즉, x축(확률)에서 우리가 원하는 클래스의 정답률이 1에 가까워질수록 y축(loss)은 0에 가까워진다.
때문에 -log를 사용한다.

아까의 점수에 exp를 취하면 위와 같은 값이 나온다. 그리고 전체를 더한 값 188.68을 각각 나눠준다. 그러면 24.5는 24.5 / 188.68로 0.13이 나오게된다. 마지막으로 원하는 정답 클래스에 -log를 취해준다. -log(0.13)은 0.89이며, 0.89만큼 안좋다라고 평가할 수 있다. 0.13이 1에가까울수록Li가 0으로간다. 0에가까울수Li가인피니티로간다.
지금까지 내용을 정리해보면, 우리에세 데이터셋 x와 y가 있고, 입력 x로부터 스코어를 얻기위해 linear classifier를 사용한다.
SVMLOSS와 CROSS-ENTROPY LOSS 손실함수를 이용해서 모델의 예측 값이 정답에 비해 얼마나 별로인지 측정한다. 그리고 모델의 ‘복잡함’과 ‘단순함’을 통제하기 위해 손실 함수 regularization term을 추가한다. 여기까지 우리가 supervised learning이라고 부르는 것에 대한 전반적인 개요를 알아보았다.
다시 한번 용어를 정리하자. 머신러닝은 AI를 만들기 위한 한 방법이다. (기계가 지능을 가지도록 스스로 학습하는 것을 머신러닝이라고 한다.) AI는 (인공지능) 사람이 수행하는 지능적인 작업을 컴퓨터가 모방할 수 있도록 하는 모든 기술을 말한다. 즉, 인간의 지능을 기계로 구현하는 것이 바로 인공지능이다.
4강부터는 데이터를 통해 자동으로 규칙을 학습하는 머신러닝의 방법에는 다양한 알고리즘들 중 인간의 뇌를 구성하는 뉴런에 영감을 받는 것이 신경망 또는 인공신경망에 대해 더 가까이 다가가는 강의이다. 이러한 신경망을 구성하는 기본 단위를 퍼셉트론이라고 한다. 신경망의 구조는 입력층-은닉층-출력층으로 이루어져 있으며 입력층으로부터 주입된 데이터를 은닉층에서 활성화 함수를 거쳐 규칙을 찾아낸다. 활성화 함수는 입력 데이터를 적절하게 변환해주는 함수다. 그리고 마지막으로 출력층에서 결과를 출력하게 된다. 데이터를 통해 규칙을 찾아내기 위해서는 신경망을 학습해야 하는데 이때 경사하강법과 역전파 알고리즘이 사용된다.
- 손실함수: 신경망 학습이 잘되고 있는지를 확인할 때 손실 함수를 사용한다. 비용 함수, 목적함수, 오차함수로 다양하게 부르고 있다.
- 경사하강법: 신경망을 데이터에 최적화하기 위해 손실함수의 경사를 구하고 기울기가 낮은 쪽으로 계속 이동시킨다. 예를 들어 산을 내려가는 것이 우리의 목적이라면 산을 내려가기 위해서 경사를 따라 아래쪽으로 계속 내려갈 수 있게 하는 방법을 의미한다.
- 역전파 알고리즘: 딥러닝 네트워크 구조에서 입력을 통하여 나온 경사(미분값)를 역방향으로 다시 보내어 신경망을 업데이트하는 방법이다.
출처 : https://sunnyyanolza.tistory.com/22