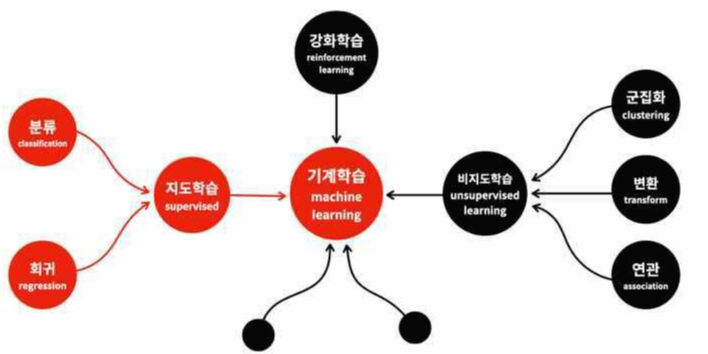
그림_1: 머신러닝은 데이터에 따라 그림과 같은 카테고리로 정리된다.
따라서 머신러닝 프로세스 중에서 가장 중요한 과정은 데이터를 이해하고 그 데이터가 내가 해결하고자 하는 문제와 어떤 관련이 있는지를 이해하는 것이 가장 중요하다. (시작이 반이랬지만, 혹자는 머신러닝에서 데이터의 중요도를 75%하고 했다. 시작은 반 이상이었다. ) 그림의 왼쪽의 회귀와 분류는 선형과 비선형을 가진다. CS231에서는 분류중에서 선형 분류에서 비선형 분류로, 지도학습에서 딥러닝으로 가는 과정을 설명한다 .
더욱 자세한 회귀와 분류의 설명은 그림의 출처로 링크를 통해서 확인하자. (필독!!)
링크자료: 회귀와 분류
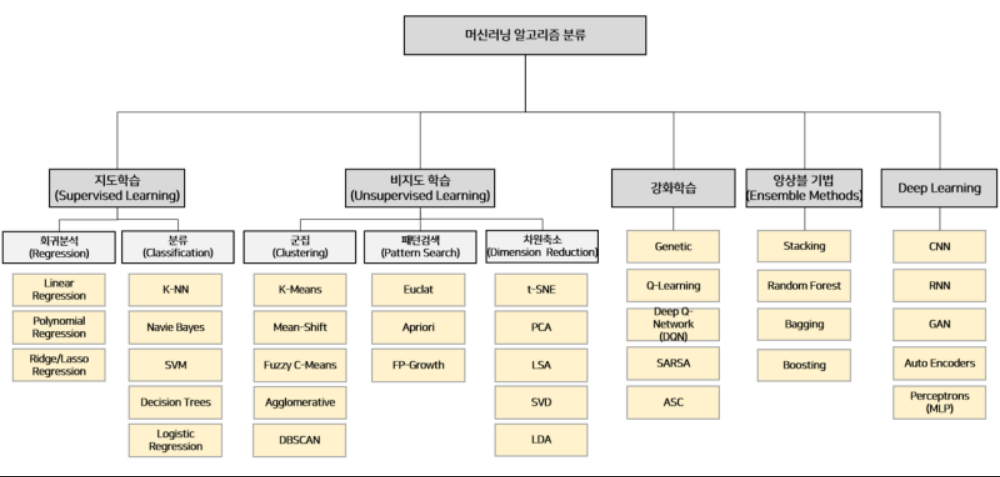
그림_2: 난 내가 배우는 알고리즘이 ML(머신러닝)인지 DL(딥러닝)인지도 혼란 스러웠다. 그림_2의 알고리즘 카테고리를 새로운 모델을 학습할 때마다, 설령 그 알고리즘이 이 분류표에 없더라도 보러오자!!. 그리고 없으면 알맞은 분류위치에 추가하자.
링크자료: 머신러닝 알고리즘 맵
그림_3: 이 그림이 머리 속에 없었다는것이 시시 때때로 얼마나 날 좌절 시켰는지 모른다. 이 그림이 그려진 순간, 이 정리글과 CS231스터디 정리 글이 비공개에서 공개로 전환될 수 있었다. 적어도 노베이스인 학습자에게 꼭 필요한 인덱싱이다.
우리가 CS231을 배우는 이유는 아마도 다음과 같다.
이미지 분류분야에서 딥러닝으로 가장 두드러진 성과가 나왔기 때문이다. Read more in relation to online casinot.
이미지넷에서 주관하는 ILSVRC라는 대회의 기록을 기준으로 컴퓨터 비젼 분야의 발전의 역사를 정리해 보자면,
2012년 Alexnet이 error 15.4%
2014년 VGGNet이 2위를 했지만 새롭고, 간단한 구조로 한단계 더 도약했다. (이 해의 우승은GoogLeNet)
2015년 ResNet 은 error가 무려 3.6% 뿐이 안되어 사함의 분류수준인 5%를 뛰어 넘었다고 한다.
딥러닝 기술로 사람을 뛰어넘는 수준의 성과가 나왔으니, 컴퓨터 비젼분야의 강의를 공부하는 건 너무 당연한 일이겠다.
나는 도대체 이걸 왜 해야하는지도 몰라서, 방황했다. 하라니까 한다만은… 솔까말.. 중요하지 않다고 생각했다.
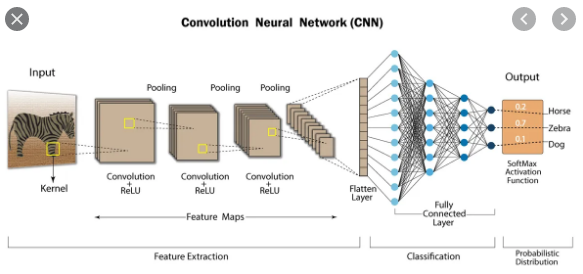
이제 자연스럽게 그림3에대한 설명으로 이어진다. 이 그림을 깨닫는 순간 정말 울뻔 했다.
이게 모라고…. 너무 기쁘고 감사했다. 그림 설명 아래 이 그림 이전에 fully connected layer를 인스톨 시켜주신 블로그를 링크해 두었으니, 꼭 읽어보길 바란다. CS231n강의의 1강~6강의 기본은 이 개념을 먼저 인스톨 한 뒤에 시작하길 추천한다.
그림_3: 딥러닝의 구조이다. 이 중 Fully connected layer가 어느 위치에 있는지 각인 시켜 두자!! 데이터가 flattern구조로 나뉜다음 만나는 활성화 함수는 Relu이다. 활성화 함수란? 필요한(가중치가 높은) 데이터는 활성화 시키고 그렇지 않은 데이터는 비활성화 시켜주는 말 그대로 활성화 함수다. 활성화된 데이터만 다음 단계로 전달된다.
예를 들어 28×28 행렬의 이미지가 784개의 flattern vector데이터로 변형되어서 Relu가 입혀지면 128개의 활성화된 vector만 머신러닝 알고리즘(모델)에 전달된다. 그렇게 학습을 마치고 나온 데이터는 다시 Softmax라는 활성화 함수를 만나 0~9개의 결과값을 만들어 내는 것이다. 이 결과값에 영향을 준 W들이 각각의 (0~9개의 탬플릿)결과에 얼마나 얼마나 나쁜 정도를 가졌는지를 수치로 판단해 주는 함수가 손실함수(LossFunction)인 것이다. 손실함수는 이 템플릿에 영향을 준 ‘W의 나쁜 정도’를 나타내 주는것이다.
그러니 수치가 크면 클수록 나쁜 W인것이므로 이 수치를 작게만들어줄 다음 W값을 찾아서 다시 하습을 반복하도록 한다.
그 과정이 최적화 즉 optimization이고, 전달해 주는 방법은 역전파 (BackPropagation)이다.
더 자세한 설명은 Fully Connected Layer에 대한 다음 링크를 꼭 읽어보자!!
출처 : https://sunnyyanolza.tistory.com/13