
사이킷런(Scikit-Learn)은 머신러닝용 라이브러리 이다.
데이터를 분류(classification), 회귀(regression), 군집화(clustering), 차원감소(demensionality reduction)하는 방법의 4가지 알고리즘을 가지고 있다.
이 중 라벨링(Labeled) 분류로 classification과 clustering이 있고, 데이터의 양으로 나뉘는 regression과 dimensionality reduce가 있다.
데이터에 따라 의사결정트리, 랜덤 포레스트, SVM 등의 모델중 어떤 모델로 학습을 시킬지 정하다.
실습과정은 데이터를 load->데이터 사이즈 fit->데이터 slpit->모델적용->평가의 단계를 가진다.
예제를 통해 머신러닝의 학습과정 및 평가과정을 정리해 보자.
사이킷런은 총 14개의 데이터 셋을 제공한다.
이 중 아이리스 데이터 셋을 가지고 3종의 아이리스로 의사결정트리 모델을 가지고 분류해 보자.
사이킷런 주요 모듈

데이터 로딩 (가져오기)
from sklearn.datasets import load_iris #사이키 런의 데이터 셋으로부터 iris를 가져온다.
iris = load_iris() #load_iris()함수로 데이터 가져오기 완료.
마찬가지로 다른 데이터 셋을 가져올때도 같은 형식으로 laod한다.
from sklearn.datasets import load_digits
digits = load_digits()

데이터 살펴보기. 불러온 데이터를 다음과 같은 방법으로 확인 할 수 있다.
dir(iris).keys()
iris.keys()
–> data, target, frame, target_names, DESCR, feature_names, filename 까지 총 6개의 정보가 있으며,
iris.data / iris.DESCR / iris.feature
print(iris_data.shape)#shape는 배열의 형상정보를 출력하여 데이터의 형태를 확인 한다.
pandas를 이용해 데이터를 DataFrame이라는 자료형으로 변환합니다.

Pandas로 데이터 구조화 하기
pandas라는 파이썬 데이터 분석 라이브러리는 Series와 DataFrame이라는 자료 구조를 제공합니다.
pandas 살펴보기. See much more information around parhaat online casinot. 자주쓰는 명령어로 배우는 Pandas
import pandas as pd # pandas를 불러오고 이후로는 pd라고 사용하겠다고 선언해 주는 코드 입니다.

데이터 분리
머신러닝을 할 때, 처음부터 데이터를 훈련 세트와 테스트 세트로 분리하여 모델 훈련 후 평가(예측)시 테스트 세트를 이용합니다.
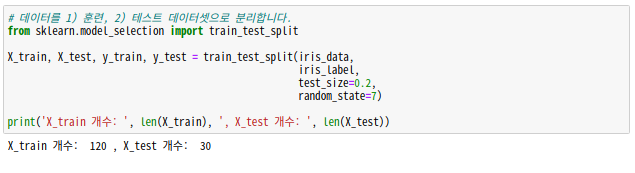
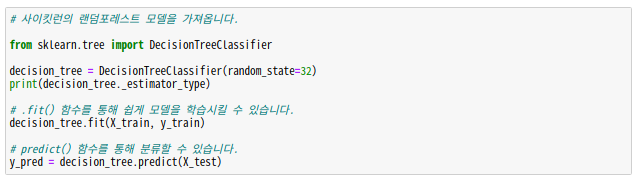
모델 학습 시키기
의사결정트리 란?
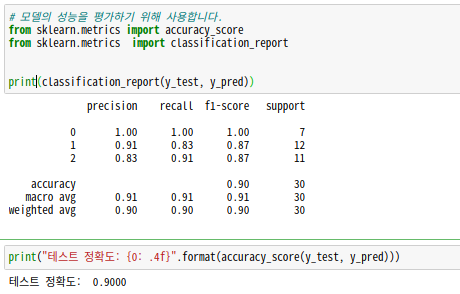
사이킷런의 metrics 모듈로 성능 평가(accuracy)하기.
그 밖의 테스트 셋트로 사이킷런을 활용한 머싱러닝 실습
그 밖의 사이크런 관련 정보 링크
출처 : https://sunnyyanolza.tistory.com/11